




| |
|
|
|
||||
|
|
||||
|
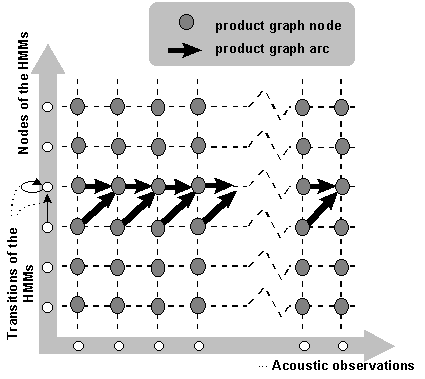
In Paper 3, I account in detail for how the best path is found in the 2-dimensional grid of Figure 5. The general principle is dynamic programming (DP), which yields a time-synchronous search, i.e., time-points are processed one at a time. Therefore the search can be performed in real time as the speaker utters a sentence. This is an important feature in human/machine dialogue where short response times often are critical for users acceptance of the systems. The Viterbi search is the most computationally demanding part of the dynamic decoding of the system described in Paper 3, but several approximations are used to keep computation down. The most important one is beam pruning. A combination of two different pruning criteria both a threshold on the path probabilities and a maximum number of alive paths are enforced. A section of Paper 3 is devoted to this topic that is of great importance for fast computation. It is shown that the combination of the pruning criteria is more efficient than each criterion by itself. |
 |
|||
|
|
||||
|
An output representation that takes better advantage of the acoustic evidence is one where the ASR module delivers a set of acoustically scored hypotheses to higher modules. These modules can then select the most likely word-string hypothesis on the basis of both the acoustical evidence computed by the ASR module, and the syntactic, semantic and pragmatic analysis. A popular representation of this set of hypotheses is an N-best list. This is simply a list of the N most likely word strings given the sequence of acoustic observation vectors. Thus, an N-best list is a generalization of the output of the Viterbi algorithm (in the case of the Viterbi algorithm, N = 1). Finding the N-best word-strings is a significantly harder problem than just finding the most likely word-string. It can be solved by extending the DP search and keeping a stack of hypotheses at each search point in Figure 5 instead of just the most likely as in the standard Viterbi algorithm. This has the advantage of preserving the time-synchronous feature of the Viterbi algorithm, but the complexity is proportional to N, i.e., the already computationally demanding algorithm becomes slower in proportion to the desired number of hypotheses. A more computationally efficient method is the so called A* (a-star) search. This method is based on the stack decoding paradigm where a search tree is built with partial hypotheses represented by paths from the root to the leaves. The word-symbols are associated with the branches of the tree (see Figure 6). During the search, most paths are partial hypotheses, i.e., they do not cover the whole utterance. The partial path that is most promising according to a search heuristic is expanded by growing new branches from its leave. When there are enough complete paths in the tree, the search is terminated. The key to an efficient A* search is the search heuristic. When evaluating partial paths, the likelihood of the words in the path so far, given the acoustic observation, is easily accessible and should of course be utilized. But it turns out that this is not enough - it is also necessary to estimate the influence of the remainder of the utterance. It is possible that a partial path with a high likelihood turns out to be in a "dead-end", and can not be completed with a high likelihood. It was an observation of Soong and Huang (1991) that made A* practically applicable to the N-best problem in ASR. They realized that the likelihoods computed in the Viterbi algorithm constitute a particularly well behaved A* heuristic. In the Viterbi search, the highest likelihoods of the observations from the beginning of the utterance to all points in the product graph (see Figure 5) are computed. If the A* search is performed backwards from the end of the utterance, the partial paths are from some interior point to the end of the utterance, and the remainder of the utterance is from the beginning to the interior point. Thus, the best possible likelihood for the remainder of the utterance is the likelihood computed in the Viterbi search. This particular heuristic has many attractive features, one is that complete paths are expanded in order of likelihood, i.e., when N complete paths with different word strings have been expanded, the search can be terminated. The development of an A* search algorithm, currently used in the WAXHOLM dialogue system has been a significant part of my work in the ASR field, and is reported on in Paper 1 and Paper 3. The most original aspect of the work in this area is the optimization of the "lexical network", introduced in Paper 1, that greatly reduces computation in the search. The optimization method is developed further in Paper 3, where the concept of word pivot arcs is introduced. Although in this case it is used only in the A* framework, word pivot arcs are relevant also in standard Viterbi decoding, because they can be used to significantly reduce the size of the product graph. |
|
|||
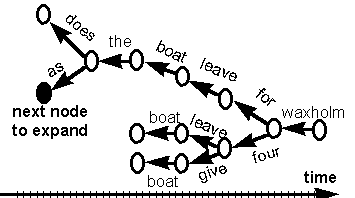
Figure 6. The search tree of a stack-search backwards from the end of an utterance. During the search, the tree is expanded by selecting the most "promising" leave and grow new word-branches from it. The key to a successful algorithm is how to determine which leave is the most promising. See the main text for details. |
||||
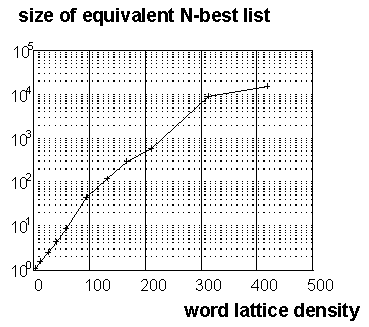
3.4 Word lattice representation of multiple hypotheses |
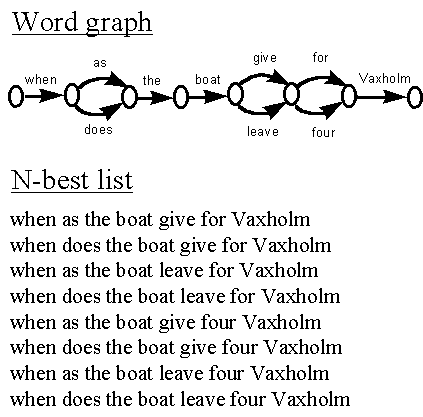 |
|||
 |
||||
| |
|