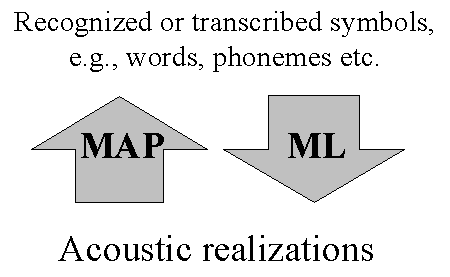
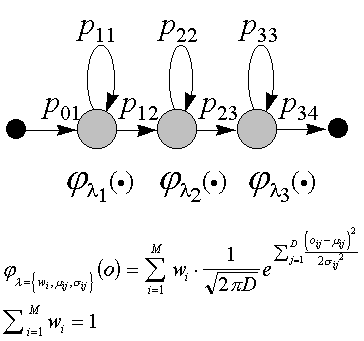In the late 1980's it was pointed out by several authors that the output
activities of ANNs trained with the back-propagation algorithm approximate
the a posteriori class probabilities (Baum and Wilczek 1988; Bourlard and
Wellekens, 1988; Gish, 1990; Richard and Lippman, 1991). In the case of
an ANN trained to recognize phonemes, this means that the ANN estimates
the probability of each phoneme given the acoustic observation vector.
This observation is of fundamental importance for the theoretical justification
of the hybrid HMM/ANN model. By application of Bayes' rule, it is easy
to convert the a posteriori probabilities to observation likelihoods, i.e,
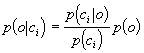 |
(1)
|
where ci is the event that phoneme i is the correct phoneme, o is
the acoustic observation, and p(ci) is the a priori likelihood of phoneme
i. The unconditioned observation probability, p(o), is a constant for all
phonemes and can consequently be dropped without changing the relative
relation between phonemes, and the a priori phoneme probabilities are easily
computed from relative frequencies in training speech data. Thus, equation
(1) can be used to define output probability density functions of a
CDHMM.
Back-propagation ANNs have intrinsically many of the features that have
been added to the standard CDHMM in the development process discussed in
the previous section. The normal back-propagation estimates MAP phoneme
probabilities, not ML estimates that is the normal estimation method for
CDHMM. As mentioned, MAP has better discrimination ability than ML, and
is a more intuitive method to train a model for recognition.
Also the parameter sharing/tying is available in the ANN at no extra cost.
This was introduced in the CDHMM with added complexity as a consequence,
to be able to use complex probability density functions without introducing
too many free parameters. In Figure 4 it is seen
that all output-units in the ANN share the intermediate results computed
in the hidden units. However, this total sharing scheme can sometimes hurt
performance and it is therefore beneficial to limit the sharing of hidden
units. This is discussed more in section 2.5.
The important short time dynamic features - formant transitions etc. -
have been captured in ANNs by time-delayed connections between units (Waibel
et al., 1987). This is a more general mechanism than the simple dynamic
features (1st and 2nd time-derivatives) used in the
standard CDHMM. One use of time-delayed connections is to let hidden units
merge information from a window of acoustic observations, e.g., a number
of frames centered at the frame to evaluate. The same mechanism can be
used to feed the activity of the hidden units at past times, e.g., the
previous time point, back to the hidden units. This yields recurrent networks
that utilize contextual information by their internal memory in the hidden
units (e.g., Robinson and Fallside, 1991). A general ANN architecture that
encompasses both time delay windows and recurrency, is presented in Paper
6.
Problems that are related to the HMM-part of the hybrid, are of course
not solved by the introduction of the ANN. The Markov assumption, the Viterbi
approximation etc. still remain. In many cases, the ad hoc solutions developed
to reduce the effects of these problems for CDHMM can easily be translated
to the hybrid environment, but in the case of context dependent models,
e.g., tri-phones, there is an extra complication. It is not as straight-forward
to apply Bayes' rule to the output activities when they are conditioned
by the surrounding phoneme identities. It turns out that, to compute the
observation likelihood in this case, the probability of the context given
the observation is needed, i.e.,
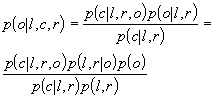 |
(2)
|
where c is the phoneme, and l and r are the right
and left context phonemes. This problem has been solved by (Bourlard and
Morgan, 1993; Kershaw, Hochberg and Robinson, 1996) by introducing a separate
set of output units for the context probabilities, p(l,r|o), but
their results indicate that the gain with tri-phones is smaller for the
hybrid model than for the standard CDHMM.
|
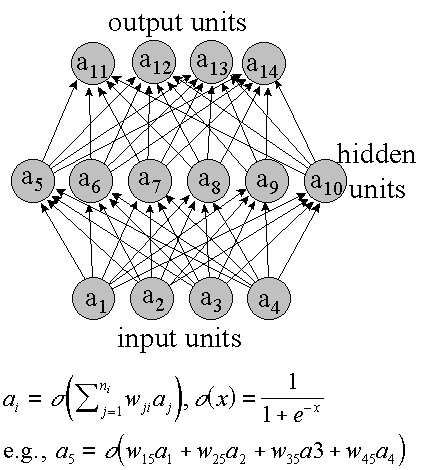
Figure 4. Graphical
representation of a feed-forward ANN. Associated with each node at each
time is an activity. This is a real bounded number, e.g., [0; 1] or [-1;
1]. The activities of the input units is the input pattern to classify.
The activities of all other units are computed by taking a weighted sum
of the activities of the units in lower layers, and then applying a compressing
function s to get a bounded value. The activities of the output units are
the networks response to the input pattern. To train an ANN for a particular
task, a training database is prepared with input patterns and corresponding
target vectors for the output units. The weights, wij, of the ANN are adjusted
to make the output units' activities as close as possible to the target
values. This is done iteratively in the so called back-propagation training. |