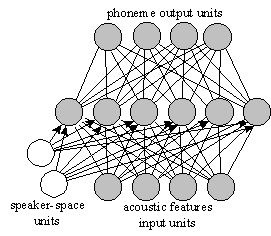
|
In the previous sections it was discussed how to model the speaker variability,
but the particular adaptation procedure is not specified. This is not a
coincident - in fact, it is one of the advantages of the speaker modeling
framework that the adaptation procedure is not determined by the model
of the variability. Different adaptation schemes may be chosen for different
tasks. For example the amount of adaptation speech available, text dependent/independent
adaptation, real-time requirements etc. may be of relevance for the particular
adaptation scheme chosen.
Clearly, speaker adaptation in the speaker modeling framework includes,
in one form or the other, estimation of the current speaker's position
in the speaker-space. If the speaker's position is known, this information
can be used to condition the phonetic evaluation, and give a more accurate
recognition. If the exact position in the speaker-space is unknown, it
must be estimated from the knowledge sources at hand. This includes speech
recorded previously from the speaker (possibly only the one utterance to
recognize), but it could also include other types of information that is
available to the system. For the analysis of the recorded speech, features
that are often discarded in ASR can potentially be of use for the speaker
characteristics estimation, e.g., fundamental frequency that is strongly
correlated with gender.
The estimation of speaker-space position need not be explicit. A concept
strongly related to speaker adaptation, is the so called speaker consistency
principle. This principle is a formulation of the observation that an utterance
is spoken by one and the same speaker, from the beginning to the end. This
constrains the observation space and can therefore be used to reduce the
variation in the ASR model. In the speaker modeling framework, the speaker
consistency principle can be introduced by enforcing constant speaker
parameters throughout the utterance. This can be implemented by adding
a new dimension to the search space of the dynamic decoding. The original
two dimensions: time and HMM state, are then complemented with the third
dimension of the speaker parameters. This is the method used in Paper 5.
The extended search space is illustrated in Figure
15.
The dynamic decoding search in the extended search space of Figure
15 is pruned with beam-pruning just like in the case of the standard
search in two dimensions. The effect is that partial hypotheses with low
probability will not be further investigated in the search, leaving more
computational resources for the most promising hypotheses. In the extended
search space, a part of an hypothesis is the speaker characteristics, so
the effect of beam pruning is that hypotheses with unlikely speaker parameters
will be pruned. In effect this is speaker adaptation - as the Viterbi search
progresses, unlikely speaker characteristics are successively pruned, and
the speaker's position in the speaker space will gradually be more specified.
Consequently, more resources can be allocated for the other dimension.
Thus, in this framework, adaptation in the sense that something in the
system is progressively changed, is the changed balance of attention in
the search from speaker characteristics to HMM states.
As a final note, we point out that the speaker modeling approach and speaker
consistency modeling does not require an ANN model - a related adaptation
scheme in the HMM domain is found in a paper by Leggeter and Woodland (1994),
and a slightly different approach to implement the speaker consistency
principle is taken by Hazen and Glass (1997). In their consistency model,
the key concept is long range correlation between speech sounds. No explicit
speaker model is used, but the method is successfully combined with speaker
clustering and a technique called "reference speaker weighting". Both of
these implicitly define speaker models by the space spanned by the clusters
and reference speakers respectively.
|
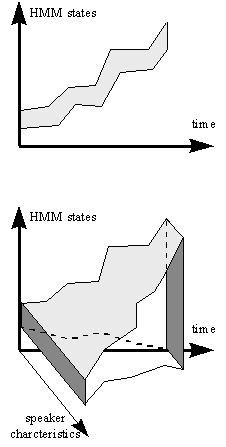 Figure 15. Search-space
of the dynamic decoding. Top: the standard search space with the two dimensions
time and HMM states. The objective of the dynamic decoding is to find the
most likely path through the search-space. Because of beam-pruning, many
paths in the search space are never investigated. This is indicated by
the shadowed "beam" in the figure. Bottom: the search space with
an additional speaker characteristics dimension. At the beginning of the
search, all different speaker characteristics are inside the beam, but
as the search progresses, unlikely speaker characteristics are successively
pruned, and the speaker's position in the speaker space is gradually
more specified.
Figure 15. Search-space
of the dynamic decoding. Top: the standard search space with the two dimensions
time and HMM states. The objective of the dynamic decoding is to find the
most likely path through the search-space. Because of beam-pruning, many
paths in the search space are never investigated. This is indicated by
the shadowed "beam" in the figure. Bottom: the search space with
an additional speaker characteristics dimension. At the beginning of the
search, all different speaker characteristics are inside the beam, but
as the search progresses, unlikely speaker characteristics are successively
pruned, and the speaker's position in the speaker space is gradually
more specified.
|