|
Continuous speech recognition (CSR), not long ago imaginable only in science-fiction
stories, is a reality today. The first commercial, large vocabulary, continuous
speech dictation system for use on standard PCs is already on the market
(Naturally SpeakingTM
by Dragon Systems), and others will follow. IBM has announced a similar
product to be released at the end of 1997. There is however a long way
to go from contemporary state-of-the-art recognition systems to a system
that is comparable with human speech perception. The research on the SWITCHBOARD
corpus of spontaneous speech over the telephone is an illustration of this
discrepancy (Cohen, 1996). For this task, today's technology is clearly
not sufficient.
Today's best large vocabulary systems are used for one speaker only, because
it is desirable to fine-tune to the speaker's voice, and the systems are
still vulnerable to noisy conditions. Also, humans have an unlimited lexicon
as new words can always be formed. This is true in particular for many
Germanic languages where there is virtually no limit on the compounding
of words. CSR systems recognize at best a few ten thousand words.
The recent commercial break-through is due to a gradual improvement in
small steps of the prevalent HMM method. The improvements have walked hand-in-hand
with the development of the computer technology that has allowed increasingly
computation demanding models and the storage of larger probabilistic grammars.
Although this development has been very fruitful, concerns have been raised
about the long term development of the field. In order to bridge the remaining
gap between human perception and automatic speech recognition, new innovative
solutions may be required. It has been argued that the presence of one
dominant technique, that has been tuned for many years, suppresses work
along such innovative lines (Bourlard, 1995). CSR is a complex process
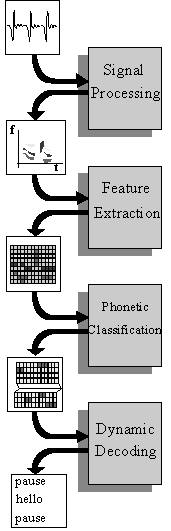
that naturally breaks down in different sub-tasks (see Figure
1)). Because of the years of tuning of the standard system, almost
any significantly new approach in one of the modules of the system will
most probably lead to an increase in error-rate when first investigated.
This thesis reports in part on work that can be characterized as tuning
the standard model, but the focus is on work on alternative methods.
In the first two blocks of Figure 1, signal processing
and feature extraction, the speech signal is transformed to a time-series
of feature vectors that is a suitable representation for the subsequent
statistical phonetic evaluation in the next module. The sample rate of
the feature vectors is usually about 100 Hz. These first two blocks are
often called the front-end of the ASR system. Apart from the implementation
of a few of the most popular features, e.g., mel-frequency cepstrum coefficients,
the work reported on in this thesis is not much concerned with the front-end.
The standard method for implementing the phonetic classification module
is to evaluate the feature vectors phonetically using multivariate Gaussian
probability density functions. The density functions are conditioned by
the phoneme in context, i.e., they estimate the likelihood of the feature
vector given the hypothesized phoneme and its neighboring phonemes. However,
several alternative methods have been proposed. For example, Digalakis,
Ostendorf and Rohlicek (1992) use a stochastic model of phone-length segments
instead of evaluation of the feature vectors independently, and Glass,
Chang, and McCandless (1996) use a method based on phone-length segment
feature-vectors and discrete landmarks in the speech signal.
Another alternative approach is the hybrid HMM/ANN method (Bourlard and
Wellekens, 1988), where an ANN is used for the phonetic evaluation of the
feature vectors. The hybrid HMM/ANN method is used in Paper 3, Paper 5
and Paper 6 of this thesis and is discussed in more detail in the next
section of this summary.
The dynamic decoding module is where the recognition system searches
for sequences of words that match phoneme sequences with high likelihood
in the phonetic evaluation. This is also the module where the probabilistic
grammar is included. Thus, word sequences are evaluated on the merits of
their phonetic match and their grammatical likelihood. The output from
the module is the most likely sequence of words, or a set of likely word
sequence hypotheses that are then further processed by other modules of
the system.
The dynamic decoding search of a large vocabulary CSR system can be computationally
very costly. Therefore, current research and development in this field
are dominated by computational issues. Popular themes for reducing computation
are pruning and fast search. In pruning methods, partial hypotheses that
are relatively unlikely are not pursued in the continued search. A particularly
efficient pruning is proposed in Paper 3. In fast search methods, an initial
fast, but less accurate search is used to guide a subsequent, more accurate
search, in order to pursue the most promising hypotheses.
Multi-pass methods are generalizations of fast search. In a multi pass
method, the output of the first search pass is a set of the most likely
hypotheses given the knowledge sources available in this first pass. Subsequent
passes re-score the set of hypotheses based on additional knowledge sources.
The additional knowledge sources require more computation, so it is beneficial
to apply them only on the selected set of hypotheses instead of the whole
search space. Examples of knowledge sources that can be added in later
passes are of the type that span word boundaries, e.g., higher order N-grams
in the probabilistic grammar, and tri-phones that condition on phones across
word boundaries.
A concept that can be applied to all the modules of Figure 1 is speaker
adaptation. Although the role of speaker adaptation in the human perception
process is not completely understood, there is convincing evidence that
such a process takes place. In particular, the presence of a rapid adaptation
was proposed by Ladefoged and Broadbent (1957). This process operates on
a time scale of a few syllables.
Speaker adaptation methods have been successfully applied also for ASR.
The success should be no surprise, because of the discrepancy in the performance
between speaker-dependent (SD) and speaker-independent (SI) systems (e.g.,
Huang and Lee, 1991). Different adaptation methods can be classified by
the amount of supervision required from the user and on what time-scale
they operate. At one end of the spectrum are methods that require the user
to read a sample text that is then used to re-train the system. This method
can asymptotically reach the performance of a corresponding SD system if
the size of the sample text is increased (e.g., Brown, Lee, and Spohrer,
1983; Gauvain and Lee, 1994). More advanced methods collect the speaker-dependent
sample as the system is running, and do re-training based on the data collected,
without the need of a special training session by the user. This latter
scheme is called unsupervised adaptation. However, both supervised and
unsupervised re-training methods are typically relatively slow - the adaptation
effect is significant only after a minute or more.
At the other end of the spectrum of speaker adaptation, are methods that
have access to a model of speaker variability. This additional knowledge
lets the system concentrate on adapting to voices that are likely to exist
in the population of speakers, instead of blindly trying to adapt based
on the (initially) very small sample from the new speaker. These methods
can reach a positive adaptation effect after only a few syllables of speech.
The speaker modeling approach to speaker adaptation is developed and investigated
in the context of hybrid HMM/ANN recognition in Paper 2, Paper 4 and Paper
5. However, the approach does not require an ANN model - a related adaptation
scheme in the HMM domain, is found in a paper by Leggeter and Woodland
(1994), and Hazen and Glass (1997) use a related method in a segment-based
system.
The remainder of this summary is organized in sections corresponding to
the three main directions of work: hybrid ANN/HMM recognition, dynamic
decoding, and fast speaker adaptation. The exception is section 4, that
contains previously unpublished material on the representation of large
sets of alternative hypotheses - the output of the dynamic decoding search.
Section 6 contains a brief presentation of the applications of the developed
CSR system. Finally, section 7 contains brief summaries and comments on
the included papers. In particular, the original contribution and innovative
elements of each paper are discussed in this section.
|
|